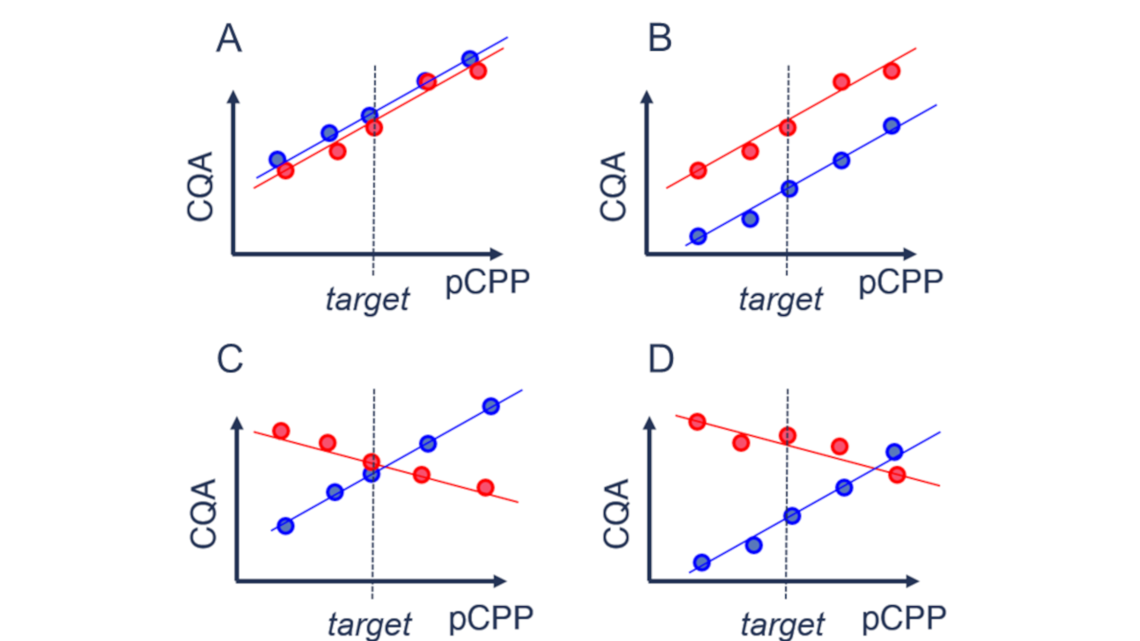
As a bioprocess scientist dealing with scale-down models, you have to find out for each critical quality attribute (CQA) whether your scale-down model is case A (predictive), B (semi-predictive), or C and D (not predictive).
Case A is desired as your scale-down model behaves similar to the manufacturing scale process. Therefore, your knowledge gained on a small scale is directly transferable to the manufacturing scale. For case B, an offset in a certain quality attribute can still be accepted if the functional behavior of this quality attribute stays similar across scales. Case C and case D are undesirable.
As manufacturing scale experiments are expensive, a commonly agreed-upon methodology for scale-down model qualification is to qualify the model on set-point conditions. With this approach, you rule out case B and case D. However, if you prove similarity on target, you still do not know whether your effects are similar (case A) or different (case C) across scales. So, case C represents the worst-case scenario, as common statistical methods cannot rule it out. Looking at it theoretically, it is less improbable that different effects (straight lines with different slopes) intersect at target (case C) than they intersect anywhere else (case D). Therefore, different effects (case B) are less likely than similar effects (case A) at similar target behavior. However, to gain absolute assurance, you need to perform large-scale experiments on other than target conditions.
Though, as discussed above, case B might still be acceptable, but regarding the patients' risk, it is better to reject similarity of your scale-down model rather too much than too little.