If a holistic approach towards utilizing data did exist, what could a solution like this be able to do?
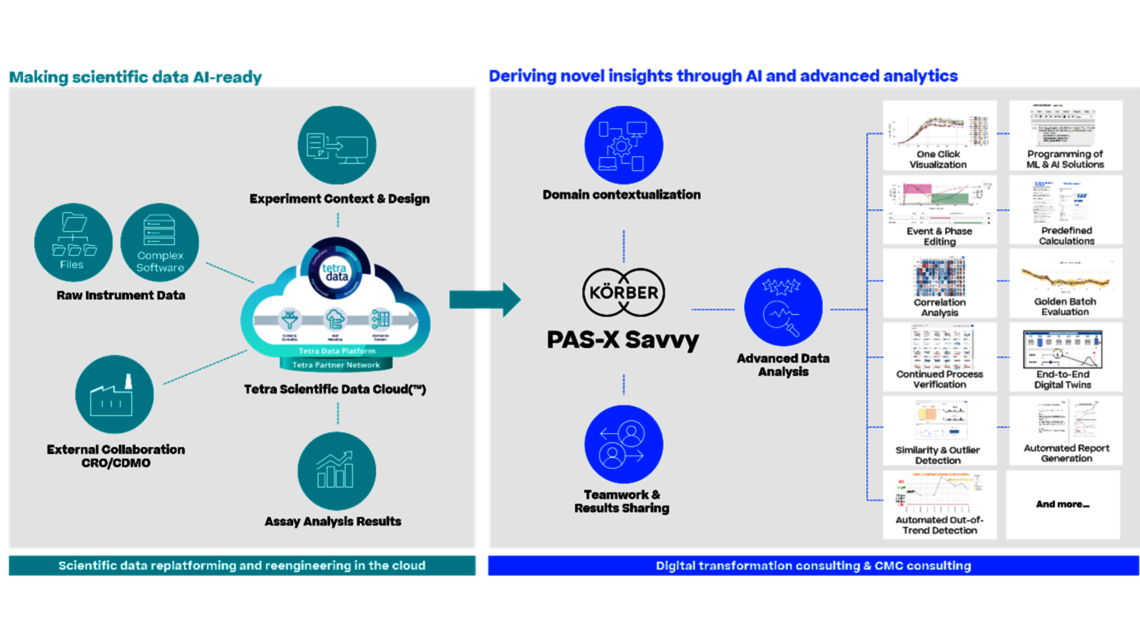
Ken: The solution could effectively address the outlined challenges, unlocking new insights and relationships within diverse datasets. It would enable AI/ML utilization to optimize processes, offering intelligence on sources of variability. Moreover, it could facilitate the creation of high-fidelity digital twins essential for bioprocess scale-up, tech transfer, and ongoing validation. The cloud-based data accessibility would ensure seamless sharing and scalability across the globe.
Christoph: Think about current solutions for multivariate data analysis: Data is copied from Excel into an isolated solution for principal component analysis. An outlier is identified, and the analyst goes back to the raw data, extracts data in Excel, and imports it again. After 6 months, no one will remember which data were used for a plot, which might have been included in an IND or BLA filing, or used to address an OOS. With a seamless solution, we avoid any doubts about data integrity, whether we are in process development or process characterization, which are not necessarily subject to Part 11 compliance, or in the regulated environment of process validation or manufacturing itself. It represents a consistent interpretation of the Pharma 4.0 guidelines.
Of course, in addition to the improved data quality by avoiding manual errors, we also achieve a significant acceleration in data handling. We free up SMEs from the manual task of copying and pasting data, allowing them to focus on what they are paid for: data analysis. This applies to all activities throughout the product life cycle.
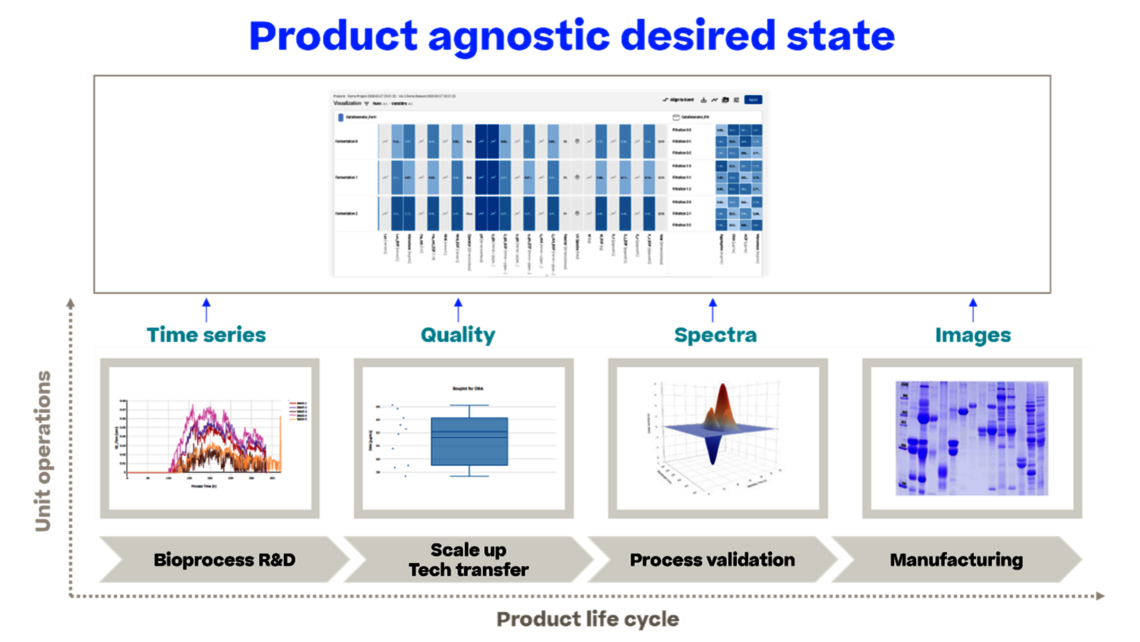
On the data analysis side, we have the potential to use all data for holistic data analysis, such as:
- analyzing interactions between unit operations rather than developing single unit operations in isolation
- linking data across different stages of the product life cycle, leading to well-informed iterations in process characterization studies and true Continued Process Verification (CPV), thus enabling continuous improvement, which is the true driver for CPV.
In essence, we develop a comprehensive control strategy that remains up-to-date, as life cycling along ICH Q12 is enabled.