Wenn es einen ganzheitlichen Ansatz für die Datennutzung gäbe, was könnte eine solche Lösung leisten?
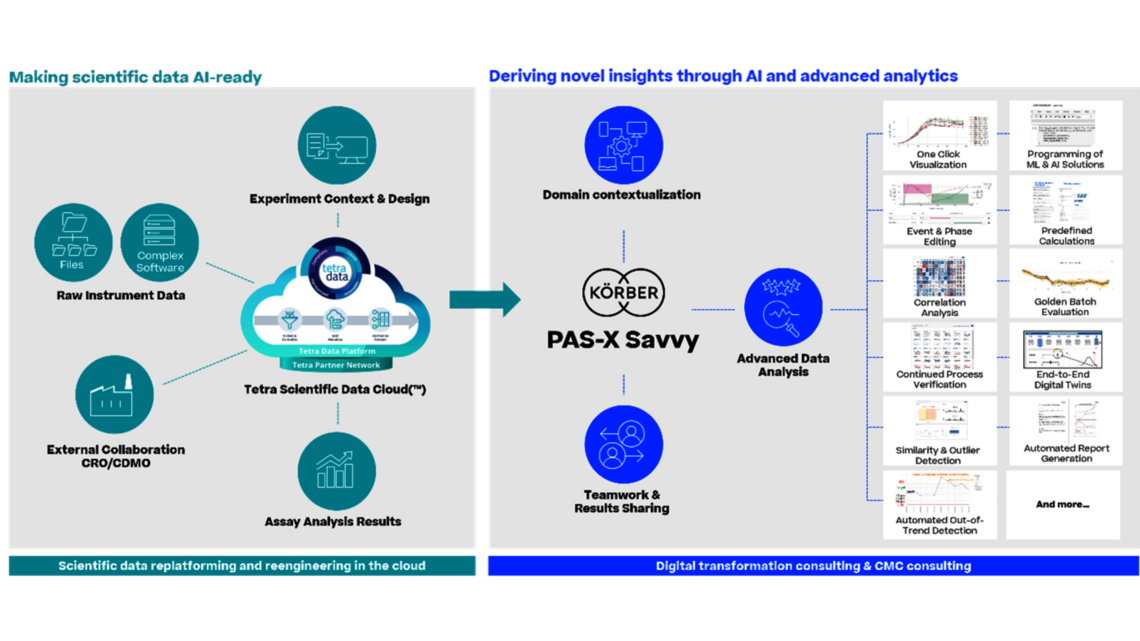
Ken: Die Lösung könnte den skizzierten Herausforderungen wirksam begegnen und neue Erkenntnisse und Zusammenhänge in verschiedenen Datensätzen aufdecken. Dies würde den Einsatz von KI/ML zur Prozessoptimierung ermöglichen und Informationen über die Quellen der Variabilität liefern. Außerdem könnte sie die Erstellung originalgetreuer digitaler Zwillinge erleichtern, die für die Skalierung von Bioprozessen, den Technologietransfer und die laufende Validierung unerlässlich sind. Der Zugriff auf die Daten in der Cloud wäre ein Garant für nahtlose gemeinsame Nutzung und Skalierbarkeit auf globaler Ebene.
Christoph: Denken Sie an aktuelle Lösungen für die multivariate Datenanalyse: Die Daten werden von Excel in eine eigenständige Insellösung kopiert, die für die Hauptkomponentenanalyse verwendet wird. Wird ein Ausreißer identifiziert, kehrt der Analytiker zu den Rohdaten zurück, extrahiert die Daten in Excel und importiert sie erneut. Nach sechs Monaten wird sich niemand mehr daran erinnern können, welche Daten für einen Plot verwendet wurden, welche in einem IND- oder BLA-Antrag enthalten sein könnten oder welche für OOS verwendet wurden. Mit einer nahtlosen Lösung vermeiden wir jeden Zweifel an der Datenintegrität, ganz gleich, ob wir uns in der Prozessentwicklung oder der Prozesscharakterisierung befinden, die nicht notwendigerweise der Part 11-Konformität unterliegt, oder in der regulierten Umgebung der Prozessvalidierung oder der Produktion selbst. Diese Lösung stellt eine konsequente Auslegung der Leitlinien für Pharma 4.0 dar..
Neben der Verbesserung der Datenqualität durch Vermeidung manueller Fehler erreichen wir natürlich auch eine deutliche Beschleunigung des Datenhandlings. Wir befreien die Fachpersonen vom manuellen Kopieren und Einfügen von Daten, damit sie sich auf das konzentrieren können, wofür sie eigentlich bezahlt werden: die Datenanalyse. Dies gilt für alle Tätigkeiten während des gesamten Produktlebenszyklus.
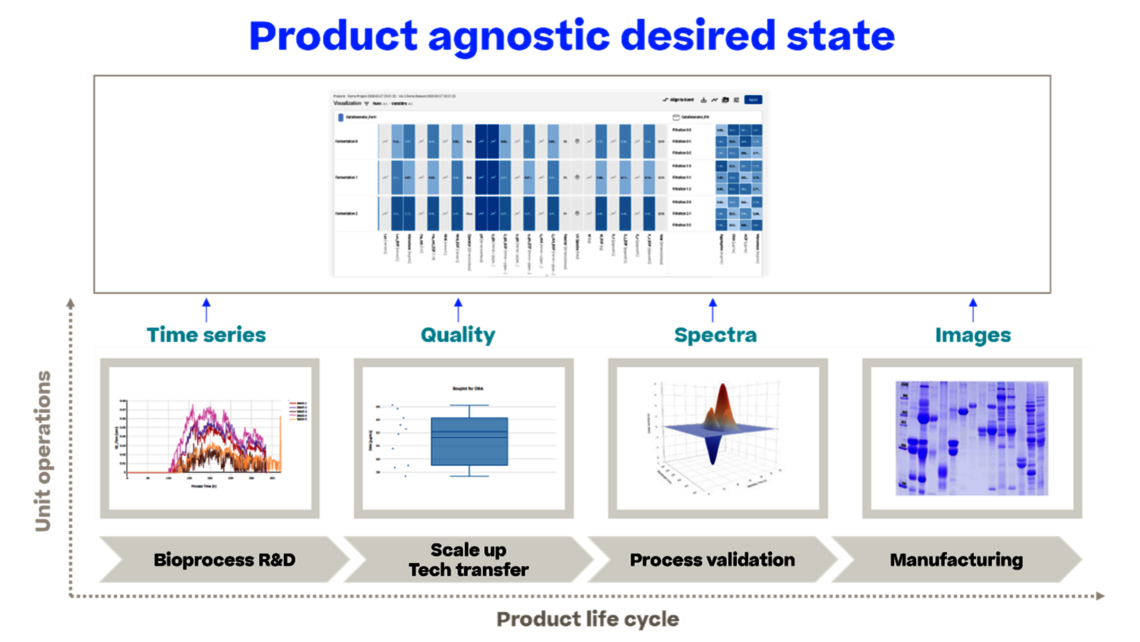
Uns bietet sich dann die Möglichkeit, alle Daten für eine ganzheitliche Datenanalyse zu nutzen, wie z.B:
- Analyse der Wechselwirkungen zwischen den einzelnen Arbeitseinheiten statt isolierter Entwicklung einzelner Arbeitseinheiten
- Verknüpfung von Daten aus verschiedenen Phasen des Produktlebenszyklus, die zu fundierten Iterationen von Prozesscharakterisierungsstudien und einer echten kontinuierlichen Prozessüberwachung (Continued Process Verification, CPV) führt und damit eine dauerhafte Verbesserung ermöglicht – die eigentliche Triebfeder der CPV.
Im Wesentlichen entwickeln wir eine umfassende Kontrollstrategie, die aufgrund eines Lebenszyklus gemäß ICH Q12 immer auf dem neuesten Stand ist.